Tech Report
Stay tuned for the upcoming release of our comprehensive technical report for more details.
Built upon the mainstream diffusion transformer paradigm, Wan 2.1 achieves significant advancements in generative capabilities through a series of innovations, including our novel spatio-temporal variational autoencoder (VAE), scalable pre-training strategies, large-scale data construction, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility.
3D Variational Autoencoders
We propose a novel 3D causal VAE architecture specifically designed for video generation. We combine multiple strategies to improve spatio-temporal compression, reduce memory usage, and ensure temporal causality. These enhancements not only make our VAE more efficient and scalable but also better suited for integration with diffusion-based generative models like DiT.
To efficiently support the encoding and decoding of arbitrarily long videos, we implement a feature cache mechanism within the causal convolution module of 3D VAE.Specifically, the number of video sequence frames follows the 1 + T input format, so we divide the video into 1 + T/4 chunks, which is consistent with the number of latent features. When processing input video sequences, the model employs a chunk-wise strategy where each encoding and decoding operation handles only the video chunk corresponding to a single latent representation. Based on the temporal compression ratio, the number of frames in each processing chunk is limited to at most 4, which effectively prevents GPU memory overflow.
Experimental results indicate that our video VAE exhibits highly competitive performance across both metrics, showcasing a compelling dual advantage of superior video quality and high processing efficiency. It is worth noting that under the same hardware environment (i.e., a single A800 GPU), our VAE's reconstruction speed is 2.5 times faster than the existing SOTA method (i.e., HunYuanVideo). This speed advantage will be further demonstrated at higher resolutions due to the small size design of our VAE model and the feature cache mechanism.
Video Diffusion DiT
Wan AI 2.1 is designed using the Flow Matching framework within the paradigm of mainstream Diffusion Transformers. In the architecture of our model, we utilize the T5 Encoder to encode input multi-language text, incorporating cross-attention within each transformer block to embed the text into the model structure. Additionally, we employ a Linear layer and SiLU layer to process the input time embeddings and predict six modulation parameters individually. This MLP is shared across all transformer blocks, with each block learning a distinct set of biases. Our experimental findings reveal a significant performance improvement with this approach at the same parameter scale. Therefore, we implement this architecture in both the 1.3B and 14B models.
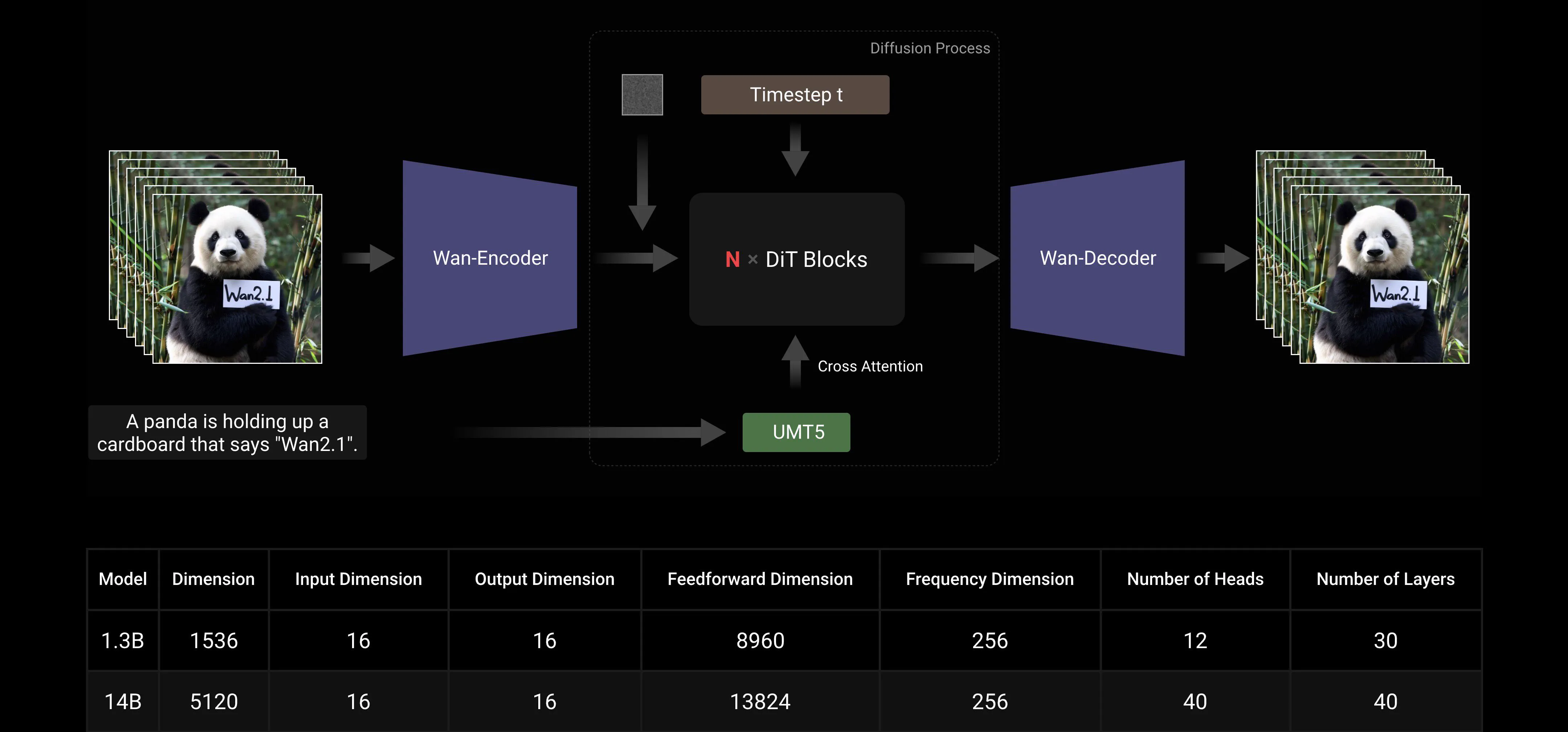
Model Scaling And Training Efficiency
During training, we employ FSDP for model sharding, when combined with context parallelism (CP), the FSDP group and the CP group intersect rather than forming a nested combination of model parallelism (MP) and CP/DP. Within FSDP, the DP size equals the FSDP size divided by the CP size. After satisfying memory and single-batch latency requirements, we use DP for the scaling.
During Inference, to reduce the latency of generating a single video when scaling to multiple GPUs, it is necessary to select Context Parallel for distributed acceleration. Additionally, when the model is large, model sharding is required.
Model Sharding Strategy: For large models such as the 14B, model sharding must be considered. Given that sequence lengths are typically long, FSDP incurs less communication overhead compared to TP and allows for computation overlap. Therefore, we choose the FSDP method for model sharding, consistent with our training approach (note: only sharding weights without implementing data parallelism).
Context Parallel Strategy: Utilizing the same 2D Context Parallel approach as during training: employing RingAttention for the external layer (inter-machine) and Ulysses for the internal layer (intra-machine).
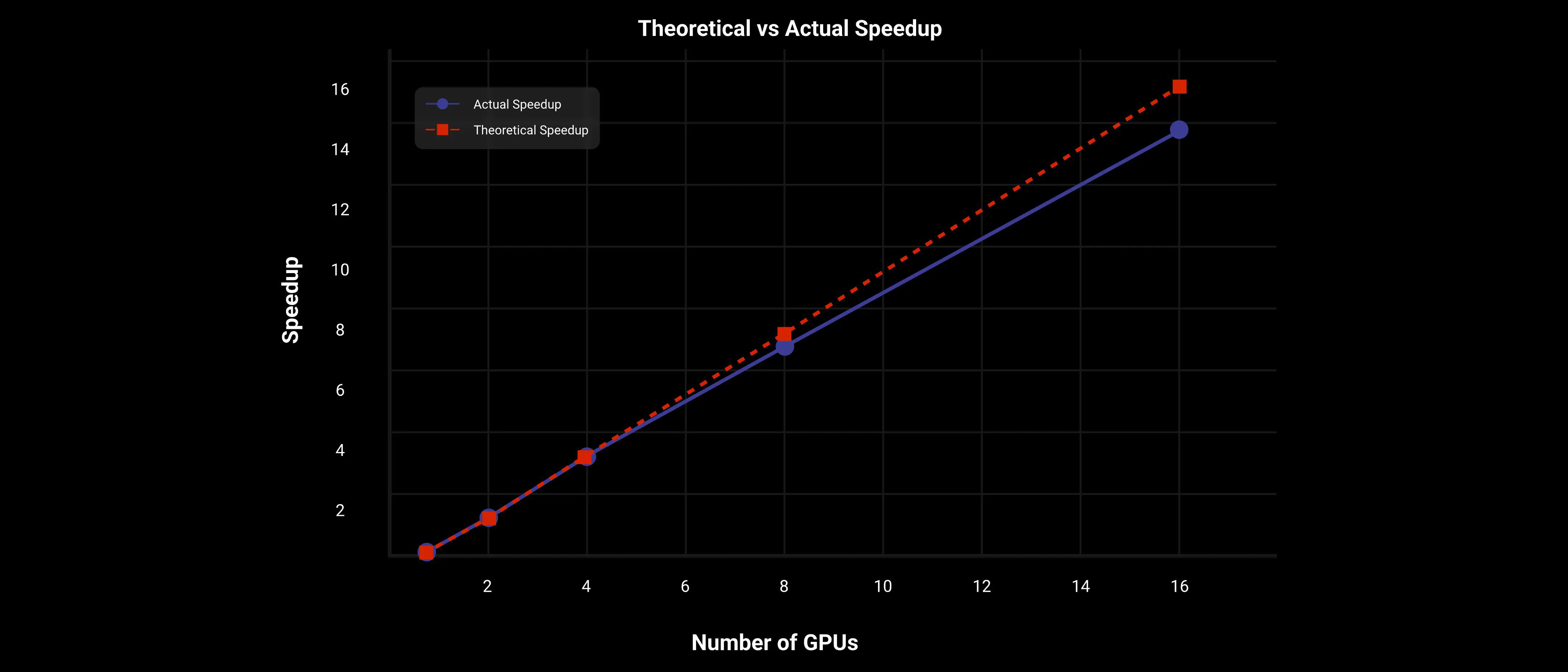
On the Wan AI 2.1 14B large model, using the 2D Context Parallel and FSDP parallel strategy, DiT achieves nearly linear speedup, as shown in the following figure.
We test the computational efficiency of different Wan AI 2.1 models on different GPUs in the following table. The results are presented in the format: Total time (s) / peak GPU memory (GB).
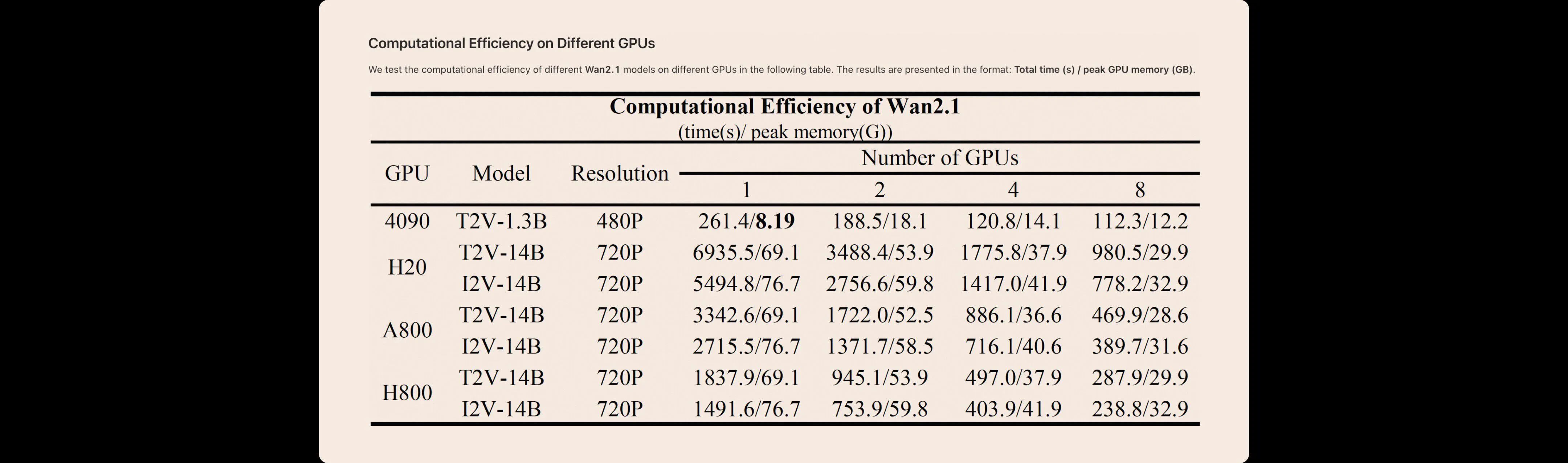
Image-to-Video
Image-to-Video (I2V) task aims to animate a given image into a video based on an input prompt, which enhances the controllability of the video generation. We introduce an additional condition image as the first frame to control the video synthesis. Specifically, the condition image is concatenated with zero-filled frames along the temporal axis, forming guidance frames. These guidance frames are then compressed by a 3D Variational Autoencoder (VAE) into a condition latent representation. In addition, we introduce a binary mask where 1 indicates the preserved frame and 0 denotes the frames that need to be generated. The spatial size of the mask matches the condition latent representation, but the mask shares the same temporal length as the target video. This mask is then rearranged into a specific shape corresponding to the VAE's temporal stride. The noise latent representation, condition latent representation, and rearranged mask are concatenated along the channel axis and passed through the proposed DiT model. Since the input to the I2V DiT model has more channels than the text-to-video (T2V) model, an additional projection layer is used, initialized with zero values. Moreover, we use a CLIP image encoder to extract feature representations from the condition image. These extracted features are projected by a three-layer multi-layer perceptron (MLP), which serves as the global context. This global context is then injected into the DiT model via decoupled cross-attention.
Data
We curate and deduplicate a candidate dataset comprising 1.5 billion videos and 10 billion images, sourced from both internal copyrighted sources and publicly accessible data. In the pretraining phase, our goal is to select high-quality and diverse data from this expansive yet noisy dataset to facilitate effective training. Throughout the data mining process, we design a four-step data cleaning process, focusing on fundamental dimensions, visual quality, and motion quality.
Comparisons vs SOTA
We curate and deduplicate a candidate dataset comprising 1.5 billion videos and 10 billion images, sourced from both internal copyrighted sources and publicly accessible data. In the pretraining phase, our goal is to select high-quality and diverse data from this expansive yet noisy dataset to facilitate effective training. Throughout the data mining process, we design a four-step data cleaning process, focusing on fundamental dimensions, visual quality, and motion quality.
We test the computational efficiency of different Wan AI 2.1 models on different GPUs in the following table. The results are presented in the format: Total time (s) / peak GPU memory (GB).