Alibaba Cloud's video generation model, Wan 2.1 (Wan), has been open-sourced under the Apache 2.0 license. This release includes all inference code and weights for both the 14B and 1.3B parameter versions, supporting both text-to-video and image-to-video tasks. Developers worldwide can access and experience the model on GitHub, HuggingFace, and Modao community.
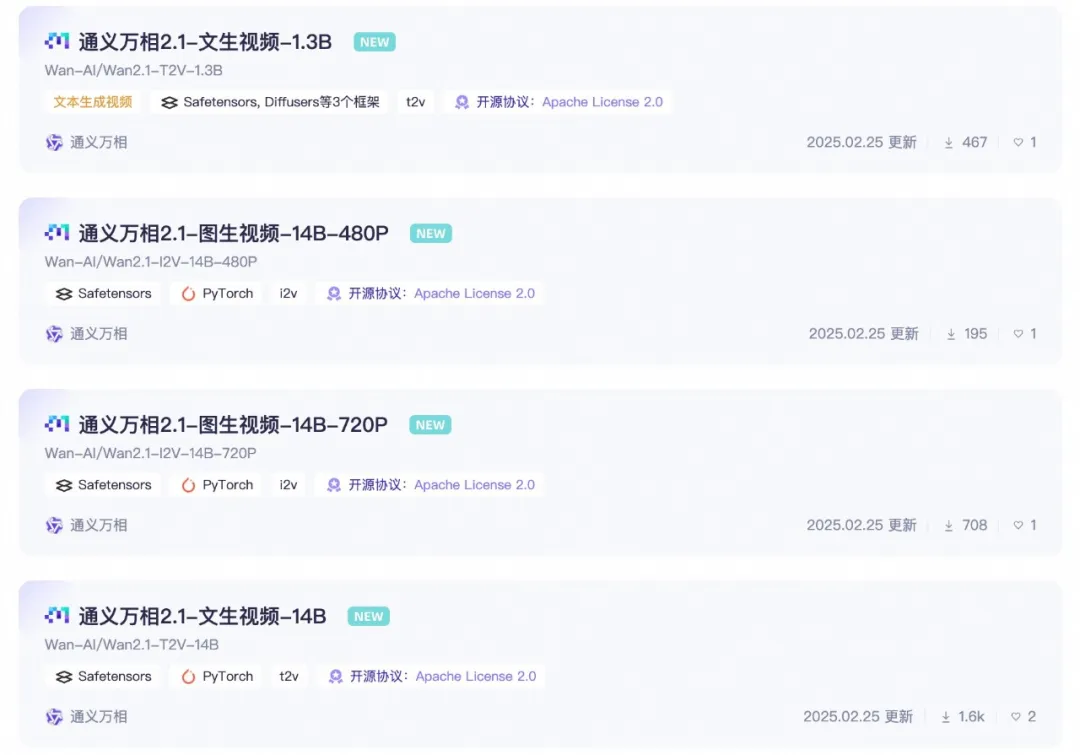
Open-Sourced Parameter Versions of the Model:
14B Version of Wan 2.1 Model
- Performance: Excels in instruction following, complex motion generation, physical modeling, and text-to-video generation.
- Benchmark: Achieved a total score of 86.22% in the authoritative VBench evaluation set, significantly surpassing other models like Sora, Luma, and Pika, and ranking first.
1.3B Version of Wan 2.1 Model
- Performance: Outperforms larger open-source models and even matches some closed-source models.
- Hardware Requirements: Can run on consumer-grade GPUs with only 8.2GB of VRAM, capable of generating 480P videos.
- Applications: Suitable for secondary model development and academic research.
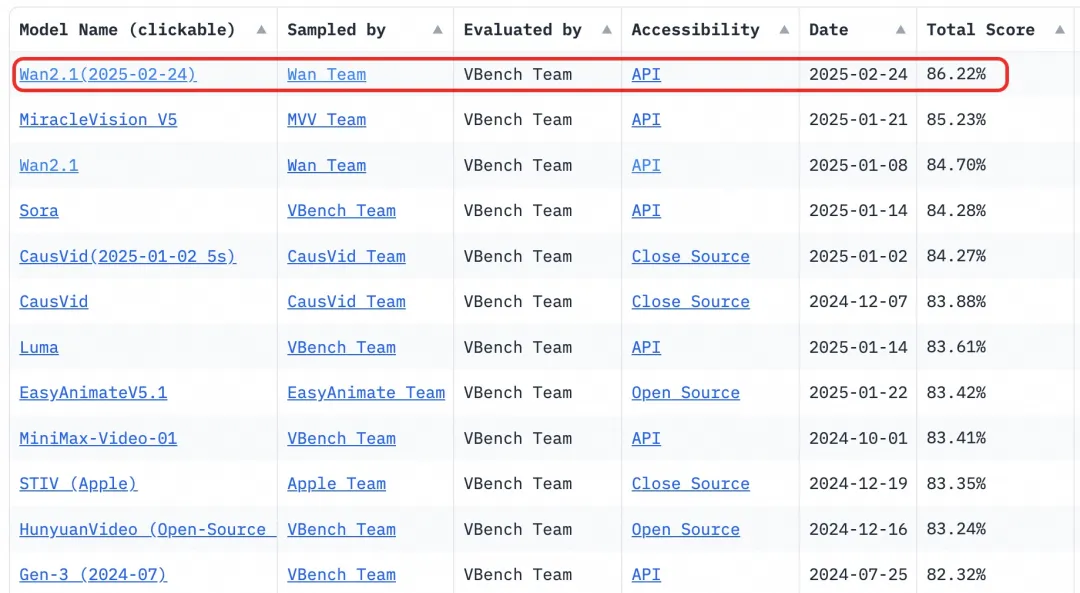
Since 2023, Alibaba Cloud has been committed to open-sourcing large models. The number of derivative models from Qwen has surpassed 100,000, making it the largest AI model family globally. With the open-sourcing of Wan 2.1, Alibaba Cloud has now fully open-sourced its two foundational models, achieving open-source status for multimodal, full-scale large models.
Technical Analysis of Wan 2.1 (Wan) Model
Model Performance
The Wan 2.1 model outperforms existing open-source models and top commercial closed-source models in various internal and external benchmark tests. It can stably demonstrate complex human body movements such as spinning, jumping, turning, and rolling, and accurately reproduce complex real-world physical scenarios such as collisions, rebounds, and cuts.

In terms of instruction-following capabilities, the model can accurately understand long textual instructions in both Chinese and English, faithfully reproducing various scene transitions and character interactions.

Key Technologies
Based on the mainstream DiT and linear noise schedule Flow Matching paradigms, the Wan AI Large Model has achieved significant progress in generative capabilities through a series of technological innovations. These include the development of an efficient causal 3D VAE, scalable pre-training strategies, the construction of large-scale data pipelines, and the implementation of automated evaluation metrics. Together, these innovations have enhanced the overall performance of the model.
Efficient Causal 3D VAE: Wan AI has developed a novel causal 3D VAE architecture specifically designed for video generation, incorporating various strategies to improve spatiotemporal compression, reduce memory usage, and ensure temporal causality.
Video Diffusion Transformer: The Wan AI model architecture is based on the mainstream Video Diffusion Transformer structure. It ensures effective modeling of long-term spatiotemporal dependencies through the Full Attention mechanism, achieving temporally and spatially consistent video generation.
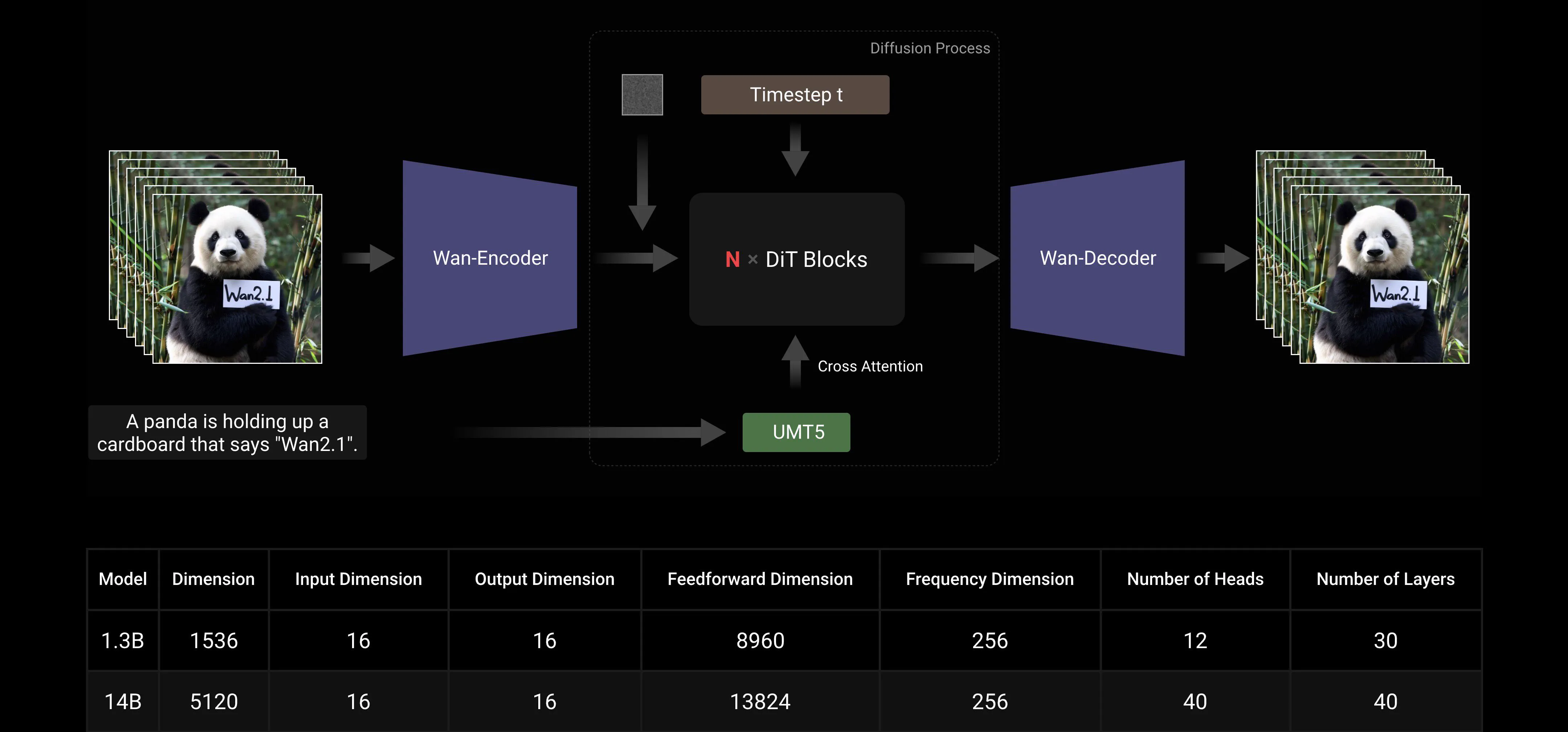
Model Training and Inference Efficiency Optimization: During the training phase, for the text and video encoding modules, we employ a distributed strategy combining Data Parallelism (DP) and Fully Sharded Data Parallelism (FSDP). For the DiT module, we adopt a hybrid parallel strategy that integrates DP, FSDP, RingAttention, and Ulysses. During the inference phase, to reduce the latency of generating a single video using multiple GPUs, we need to select Collective Parallelism (CP) for distributed acceleration. Additionally, when the model is large, model slicing is also required.

Open-Source Community Friendly
Wan AI has fully supported multiple mainstream frameworks on GitHub and Hugging Face. It already supports Gradio experience and parallel accelerated inference with xDiT. Integration with Diffusers and ComfyUI is also being rapidly implemented to facilitate one-click inference deployment for developers. This not only lowers the development threshold but also provides flexible options for users with different needs, whether for rapid prototyping or efficient production deployment.
Open-Source Community Links:
Github: https://github.com/Wan-Video HuggingFace: https://huggingface.co/Wan-AI
Appendix: Wan AI Model Demo Showcase
The first video generation model that supports Chinese text generation and simultaneously enables text effects generation in both Chinese and English:
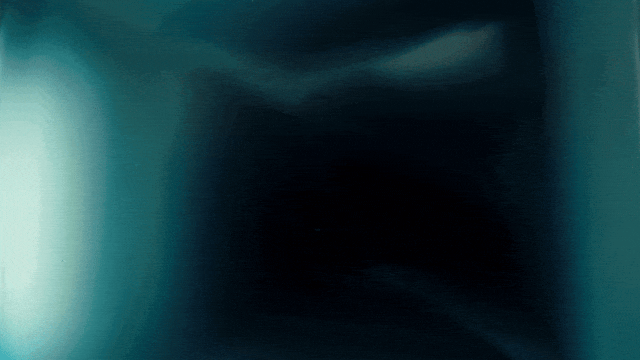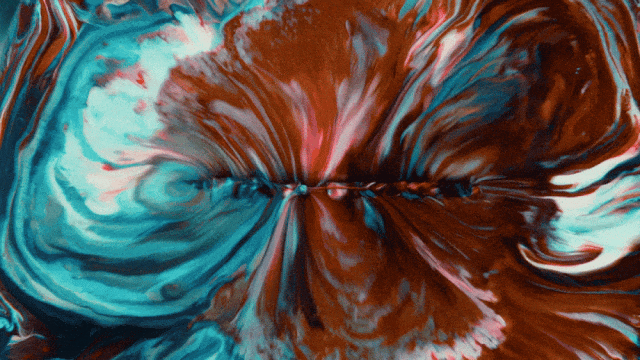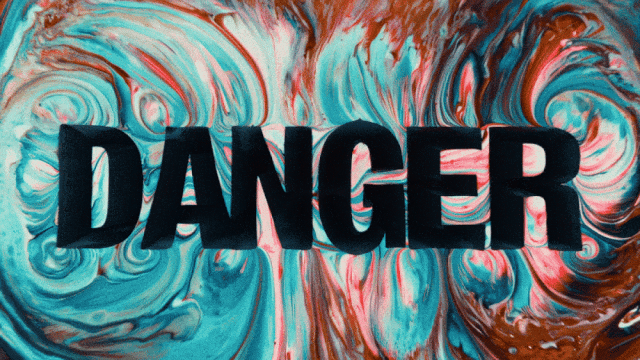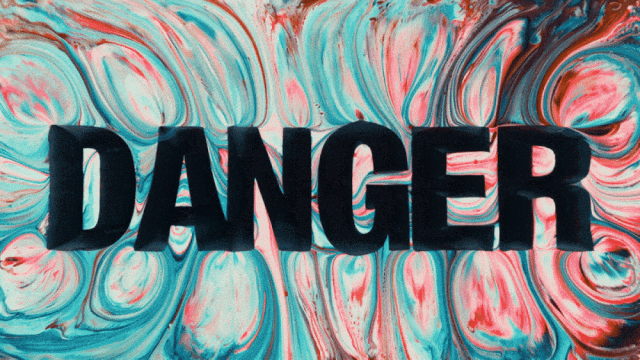
 More Stable and Complex Motion Generation Capabilities:
More Stable and Complex Motion Generation Capabilities:

 More Flexible Camera Control Capabilities::
More Flexible Camera Control Capabilities::

 Advanced Texture, Diverse Styles, and Multiple Aspect Ratios:
Advanced Texture, Diverse Styles, and Multiple Aspect Ratios:
 Image-to-Video Generation, Making Creation More Controllable:
Image-to-Video Generation, Making Creation More Controllable:

